Difference between revisions of "Matchcode Optimization"
| Line 9: | Line 9: | ||
[[File:MCO_Evaluate_Optimized.png|link=]] | [[File:MCO_Evaluate_Optimized.png|link=]] | ||
<gallery> | |||
File:MCO_Evaluate_Warning.png | |||
File:MCO_Evaluate_Sub.png | |||
</gallery> | |||
Revision as of 17:55, 20 September 2018
This page is still under construction!
Melissa Data strives to give you the most complete and up-to-date information about our products as possible. To do this, we must maintain our documentation. This means the content may not be complete or correct. Use at your own risk!
|
Evaluate Matchcode
To help you understand the effect of constructing and implementing a sub-optimal matchcode, the Evaluate Matchcode feature evaluates the five critical areas of a matchcode which determine whether one can expect the best throughput when running a process. Evaluate matchcode will indicate if your matchcode is optimized, has a warning, or is sub optimal.
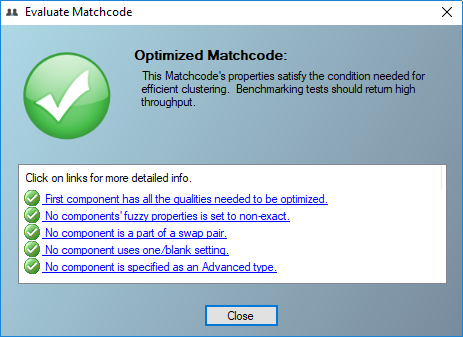


Five Critical Matchcode Areas
First Component Used in All Set Columns
When the first component is not checked (not evaluated) in all used combinations, processing will be very slow, as matchkeys cannot be grouped by that first component into optimal neighborhood clusters.
Fuzzy Settings
If a component uses a fuzzy algorithm other than exact, each record compared will produce speed penalty on keybuilding or on that algorithms required computation when deduping.
Swap Matching
When each key is compared, swapping one records values (for example: an inverse name format) and reattempting to identify a match will produce slower processing speeds.
Blank Matching
Allowing one of the 2 values being compared to either be blank or a single initial will require the matchup engine to make an extra comparison(s) and will produce a speed penalty.
Advanced Matchcode Component Type
Most matchcode component types simply specify how to extract source data into a records matchkey, but Advanced types will also tell the deduping engine to perform a calculation foreach record compared, even if the Distance property is set to zero.