This wiki is no longer being updated as of December 10, 2025.
|
Pentaho:MatchUp:Component Properties
← Data Quality Components for Pentaho
Data Types
The following table lists all the available matchcode components in MatchUp.
| Component | Description |
|---|---|
| Prefix | Prefix of a personal name (Mr, Mrs, Ms, Dr) |
| First Name | A first name |
| Middle Name | A middle name |
| Last Name | A last name |
| Suffix | A suffix from a personal name |
| Gender | Male/Female/Neutral |
| First/Nickname | A representative nickname for a first name |
| Middle/Nickname | A representative nickname for a middle name |
| Department/Title | A title and/or department name [1] |
| Company | A company name |
| Company Acronym | A company's acronym [2] |
| Street Number | The street number from an address line [3] |
| Street Pre-Directional | "South" in "3 South Main St" |
| Street name | The street name from an address line |
| Street Suffix | An address suffix (St, Ave, Blvd) |
| Street Post-Directional | "North" in "3 Main St North" |
| PO Box | PO Boxes also include Farm Routes, Rural Routes, etc. |
| Street Secondary | Apartments, floors, rooms, etc. |
| Address | A single unparsed address line [4] |
| City | A city name, ZIP or Postal code is usually more accurate |
| State/Province | A state or province name |
| Zip9 | A full ZIP + 4 code (9 digits) [5] |
| Zip5 | The ZIP Code (5 digits) |
| Zip4 | The +4 extension of a ZIP + 4 code (4 digits) |
| Postal Code (Canada) | A Canadian Postal Code |
| City (UK) | A city in the United Kingdom |
| County (UK) | A county in the United Kingdom |
| Postcode (UK) | A United Kingdom Postcode |
| Country | A country |
| Phone/Fax | A phone number [6] |
| E-mail Address | An e-mail address [7] |
| Credit Card Number | A credit card number |
| Date | A date [8] |
| Numeric | A numeric field [9] |
| Proximity | Allows you to specify a maximum distance in miles between records in which a match will be possible [10] |
| General | Any general information, ID, birthday, SSN, etc. |
-
- Company, Company Acronym, Department/Title
- Frequently these components don't match exactly because of ‘noise words’ such as “the,” “and,” “agency,” and so on. MatchUp strips these words from these components.
-
- Company Acronym
- MatchUp converts any multi-word company name into an acronym (for example, “International Business Machines” is squeezed into “IBM”). Single-word company names are left as they are. This conversion is done after noise words are removed.
-
- Street Address Components
- The seven street address components (Street Number, Street Pre-Directional, Street Name, Street Suffix, Street Post-Directional, PO Box, Street Secondary) are obtained by splitting up to three address lines. Note that PO Box and/or Street Secondary do not have to appear on their own line, or in a particular field. MatchUp's proprietary “street smart” splitter does all of the work.
-
- Full Address
- When using the Full Address component, you are at the mercy of every little deviation in data entry. Because MatchUp’s street splitter is so powerful, it is preferable to use street address components instead of the Full Address in nearly all cases. The only exception may be when processing foreign addresses that don’t conform very well to US, Canadian or UK addressing formats. This is discussed in more detail starting on page 178.
-
- Zip9, Zip5, Zip4, Canadian Postal Code
- MatchUp removes dashes and spaces from Zip codes. When processing a mix of Canadian Postal Codes and US Zip Codes, use the Zip9 component.
-
- Phone Number
- MatchUp removes non-numeric characters from phone numbers. Leading ‘1-’ and trailing extensions are stripped if present. Numbers lacking an area code are right justified so that the local dialing code and number are aligned with numbers having area codes. If a data table often has missing or inaccurate area codes (i.e., after a recent area code split), start at the 4th position of the phone number component. Do not use the right-most 7 positions, as badly formatted extensions can sometimes cause the phone number to get coded improperly.
-
- E-Mail Address
- MatchUp removes illegal characters from e-mail addresses. Incomplete, changed, and commonly misspelled domain names are corrected using the Email Address data table.
-
- Date
- MatchUp allows you to specify a number of days for which a match will be possible if the records being compared fall within the set number of days apart.
-
- Numeric
- This allows you to specify an integer number for which a match will be possible if the record’s unit difference falls within the set number.
-
- Proximity
- The proximity component requires you to map in Latitude / Longitude coordinates (Not determined by MatchUp. Can be determined by a product such as GeoCoder or Contact Verify) allowing you to match addresses within a maximum distance setting for this component.
- Size
- The maximum number of characters from this component to be used by this matchcode. If the data has fewer characters, it will be padded with spaces. Sizing is done after all other properties are applied
- Label
- (Optional) A description of the data found in this component. Not all component types use this field. Not all fields allow the label to be edited. This is most useful for clarifying the contents of General fields that don't fit any of the other component types. Max size of description is 20 characters.
- Maximum Number of Words
- This limits the number of words that MatchUp will extract from a field when building the match key. for example, if maximum words for a last name were set for 1 and the last name field was "Von Richtofen," MatchUp would only use "VON" as the last name.
- Start
- This property determines where MatchUp begins counting when applying the Size property.
- Left (beginning)
- Starts from the first character of the field. This is the most commonly used option.
- Right (end)
- Starts from the last character of the field. In other words, if the data included a phone number of "949-589-5200" and the size was 7, MatchUp would use "5895200" for the match key.
- Position
- Starts form a specific position within the field.
- Word
- Starts from the beginning of a specific word. This should only be used if a particular field always has more than one word and first word (or more) can safely be ignored.
- Trim
- This property tells MatchUp to remove excess spaces from the beginning of a piece of data, the end or both. Usually, this property is always enabled.
Matching Strategies (Fuzzy)
These properties allow for matching of non-exact components. These options are mutually exclusive, so you can only select one at a time.
- Phonetex
- (pronounced "Fo-NEH-tex") An auditory matching algorithm. It works best in matching words that sound alike but are spelled differently. It is an improvement over the Soundex algorithm described below.
- Soundex
- Another, older, auditory matching algorithm. Although the Phonetex algorithm is measurable superior, the Soundex algorithm is presented for users who need to create a machcode that emulates one from another application.
- Containment
- Match when one record's component is contained in another record. For example, "Smith" is contained in "Smithfield"
- Frequency
- Matches the characters in one record's component to the characters in another without any regard to the sequence. For example "abcdef" would match "badcfe"
- Fast Near
- A typographical matching algorithm. It works best in matching words that don't match because of a few typographical errors. Exactly how many errors is specified on a scale from 1 to 4 (1 being the tightest). The Fast Near algorithm is a faster approximation of the Accurate Near algorithm described below. The tradeoff for speed is accuracy; sometimes Fast Near will find false matches or miss true matches.
- Accurate Near
- This is a typographical matching algorithm. The Accurate Near algorithm produces better results than the Fast Near algorithm, but is slower.
- Frequency Near
- Similar to Frequency matching except that a slider lets you specify how many characters may be different between components.
- Vowels Only
- Only vowels will be compared. Consonants will be removed.
- Consonants Only
- Only consonants will be compared. Vowels will be removed.
- Alphas Only
- Only alphabetic characters will be compared.
- Numerics Only
- Only numeric characters will be compared. Decimals and signs are considered numeric.
Fuzzy Advanced
Please research the definitions of the following advanced algorithms before implementing in a matchcode.
- Jaro
- Gathers common characters (in order) between the two strings, then counts transpositions between the two common strings.
- Jaro-Winkler
- Just like Jaro, but gives added weight for matching characters at the start of the string (up to 4 characters).
- n-Gram
- Counts the number of common sub-strings (grams) between the two strings. Substring size ‘N’, is currently defaulted as 2 in MatchUp.
- Needleman-Wunch
- Similar to Accurate Near, except that inserts/deletes aren’t weighted as heavily and as compensation for keyboarding mis-hits, not all character substitutions are weighted equally.
- Smith-Waterman-Gotoh
- Builds on Needleman-Wunch, but gives a non-linear penalty for deletions. This effectively adds the ‘understanding’ that the keyboarder may have tried to abbreviate one of the words.
- Dice’s Coefficient
- Like Jaro, Dice counts matching n-Grams (discarding duplicate n-Grams).
- Jaccard Similarity Coefficient
- Very similar to Dice’s Coefficient with a slightly different calculation.
- Overlap Coefficient
- Again, very similar to Dice’s Coefficient with a slightly different calculation. String similarity algorithm based on a substring calculation.
- Longest Common Substring
- Finds the longest common substring between the two strings.
- Double MetaPhone
- Performs 2 different Phonetex-style transformations. Returns a value dependant on how many of the transformations match (ie, 1 versus 1, 1 versus 2, 2 versus 1, 2 versus 2).
- MD Keyboard
- An algorithm developed by Melissa Data which counts keyboarding mis-hits with a weighted penalty based on the distance of the mis-hit and assigns a percentage of similarity between the compared strings.
Short/Empty Settings
These settings control matching between incomplete or empty fields. They are not mutually exclusive, meaning that any combination of these settings may be selected.
![]()
- Match if both fields are blank
- Match this component if both records contain no data. This is a very important concept in creating matchcodes. See Blank Field Matching later in this chapter for more information.
- Match if one field is blank
- Will match a full word to no data (for example, “John” and “”).
- Match initial to full field
- Will match a full word to an initial (for example, “J” and “John”).
Combinations
Uses these check boxes to select which of the sixteen possible combinations will use this component. This matrix will grow as you add more components and combinations.

It is easier to visualize the effects of these boxes if you look at the list of matchcode components as well:

It is important to note that each VERTICAL column of check marks designates one acceptable matchcode. For example, the illustration above shows a combination that is made up of 4 matchcodes:
- Zip5, Last Name, First Name, Street Number, Street Name
- Zip5, Last Name, First Name, PO Box
- Zip5, Company, Street Number, Street Name
- Zip5, Company, PO Box
Since boxes 1 and 3 in the Street Number row have check marks, the Street Number field is included in matchcode 1 and 3.
Swap Match Pairs
Swap matching is the ability to compare one component to another component.
For example, if you were to swap match a First Name component and a Last Name component, you could match “John Smith” to “Smith John.” Swap matching is always defined for a pair of components. MatchUp allows you to specify up to 8 swap pairs (named “Pair A” through “Pair H”). It is strongly recommended that the other properties of both member components are identical.
Configure a Swap Pair
- Click the button for a swap pair.
- The Matchcode Editor displays the swap pair editing dialog.
- Select the two components that will be used for this swap pair. The first component is automatically disabled, since it cannot be used with swap matching.
- Select the swapping rule:
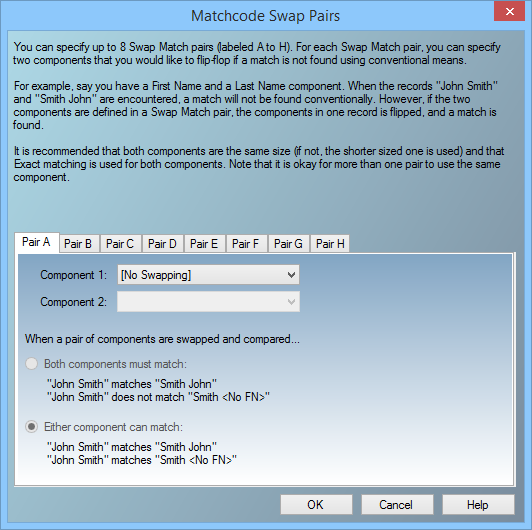
- Both components must match - The contents of both components must be a match according to fuzzy matching strategy in use for both components. "John Smith" matches "Smith John" but not "Smith <blank>."
- Either component can match - At least one of the components must match "John Smith" matches both "Smith John" and "Smith <blank>."
- Click OK. For more ideas on how to use Swap Matching, see Swap Matching Uses.