This wiki is no longer being updated as of December 10, 2025.
|
Pentaho:MatchUp:Matchcodes
← Data Quality Components for Pentaho
Component Combinations
Every matchcode is composed of one or more possible combinations of components. These represent different possible situations in which this matchcode will detect a match between two records. A match found using any one of the combinations in a matchcode is considered a match. Programmers may think in terms of a series of OR conditions. Satisfying any one of them is considered a positive result.
MatchUp allows up to 16 different combinations of components per matchcode.
Basic Example
A good example of combinations would be a matchcode designed to catch last names as well as either street addresses or post office box addresses.
- Condition #1
- ZIP/PC, Last Name, Street Number, Street Name
- Condition #2
- ZIP/PC, Last Name, PO Box
Such a matchcode might look like this:
| Component | Size | 1 | 2 |
|---|---|---|---|
| ZIP/PC | 5 | X | X |
| Last Name | 5 | X | X |
| Street # | 4 | X | |
| Street Name | 4 | X | |
| PO Box | 10 | X |
Columns 3 through 16 have been omitted for the sake of clarity. The trick to understanding this table is to look at the vertical columns of X’s. For example, looking at column 1, there are X’s in ZIP/PC, Last Name, Street #, and Street Name, indicating the goal of condition #1 exactly. In column 2 are X’s in ZIP/PC, Last Name, and PO Box, matching condition #2.
Advanced Example
For a more advanced example:
| Component | Size | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| ZIP/PC | 5 | X | X | X | X |
| Last Name | 5 | X | X | ||
| Company | 10 | X | X | ||
| Street # | 4 | X | X | ||
| Street Name | 4 | X | X | ||
| PO Box | 10 | X | X |
This matchcode produced matches under the following 4 conditions:
- Condition #1
- ZIP/PC, Last Name, Street Number, Street Name
- Condition #2
- ZIP/PC, Last Name, PO Box
- Condition #3
- ZIP/PC, Company, Street Number, Street Name
- Condition #4
- ZIP/PC, Company, PO Box
This matchcode could be used on a mailing list containing a mixture of both personal and company names and either street or PO Box™ addresses.
First Component Restrictions
The first component in any matchcode is special. This is the component that is used for clustering records, an essential element in efficient deduping. Thus, this component has certain restrictions placed on it. The Matchcode Editor enforces these restrictions automatically.
- It must appear in every combination.
- It cannot use the following types of Fuzzy matching: Containment; Frequency; Fast Near; Frequency Near; Accurate Near. All others are allowed.
- It cannot use Initial Only matching.
- It cannot use One Blank Field matching.
- It cannot use Swap Matching.
Blank Field Matching
This needs a special discussion, as its importance is often overlooked. If this property is on, then the absence of data in both records would indicate a match. If this property is off, then two records with missing data, but matching in every other way, will not match. It would be reasonable to wonder if you would not want this behavior. However, it is undesirable in certain situations. Take the following matchcode (paying attention to the Blank column):
| Component | Size | Blank | 1 | 2 |
|---|---|---|---|---|
| ZIP/PC | 5 | Yes | X | X |
| Last Name | 5 | Yes | X | X |
| Street # | 4 | Yes | X | |
| Street Name | 4 | Yes | X | |
| PO Box | 10 | Yes | X |
As described above, this produces the following combinations:
- Condition #1
- ZIP/PC, Last Name, Street Number, Street Name
- Condition #2
- ZIP/PC, Last Name, PO Box
For this example, take the following records:
| Name: | Joe Smith | Suzi Smith |
|---|---|---|
| Address: | 326 Main Street | 405 Main St |
| City/State/PC: | Pembroke MA 02066 | Pembroke, MA 02066 |
The following matchcode keys would be generated:
| Cond# | ZIP/PC | Last Name | Street # | Street Name | PO Box |
|---|---|---|---|---|---|
| 1 | 02066 | SMITH | 326 | MAIN | |
| 2 | 02066 | SMITH | 405 | MAIN |
According to these matchcode keys, it is clear that these two records do not satisfy condition #1. But because blank field matching is selected, they do satisfy condition #2. The Zip/PC, Last Name, and PO Box are exactly the same. Therefore, the two records do match.
Obviously, this is not the correct result. Making one change to the matchcode:
| Component | Size | Blank | 1 | 2 |
|---|---|---|---|---|
| ZIP/PC | 5 | Yes | X | X |
| Last Name | 5 | Yes | X | X |
| Street # | 4 | Yes | X | |
| Street Name | 4 | Yes | X | |
| PO Box | 10 | No | X |
The same comparison is done for combination #2, but the match is disallowed this time because the matchcode now indicates that missing (blank) information is not allowed to figure in the matching condition.
Looking at another example (using the same matchcode):
| Name: | Joe Smith | Suzi Smith |
|---|---|---|
| Address: | PO Box 123 | PO Box 456 |
| City/State/PC: | Pembroke MA 02066 | Pembroke, MA 02066 |
This pairing produces the following matchcode keys:
| Cond# | ZIP/PC | Last Name | Street # | Street Name | PO Box |
|---|---|---|---|---|---|
| 1 | 02066 | SMITH | 123 | ||
| 2 | 02066 | SMITH | 456 |
This record has the same problem as before, but this time combination #1 is the cause.
An even better matchcode would be:
| Component | Size | Blank | 1 | 2 |
|---|---|---|---|---|
| ZIP/PC | 5 | Yes | X | X |
| Last Name | 5 | Yes | X | X |
| Street # | 4 | No | X | |
| Street Name | 4 | No | X | |
| PO Box | 10 | No | X |
This is one matchcode that works well. There is one more possible tweak, however: Turn on Both Blank Fields for the Street # component. Occasionally, MatchUP Object may encounter records such as:
| Name: | Joe Notarangello | Suzi Notarangello |
|---|---|---|
| Address: | Oceanfront Estates | Oceanfront Est. |
| City/State/PC: | Pembroke, MA 02066 | Pembroke, MA 02066 |
This reflects a trend in up-scale neighborhoods, where neither street address has a Street # component, though it is very likely these records should match.
So this new improved matchcode will account for these situations:
| Component | Size | Blank | 1 | 2 |
|---|---|---|---|---|
| ZIP/PC | 5 | Yes | X | X |
| Last Name | 5 | Yes | X | X |
| Street # | 4 | Yes | X | |
| Street Name | 4 | No | X | |
| PO Box | 10 | No | X |
Matchcode Mapping
Matchcodes deal with the abstract. The components in a matchcode represent specific types of data, but they aren't directly linked to the fields in databases. Mapping creates the link between the data and the matchcode.
For example, take the following matchcode:
| Component | Size | Fuzzy | 1 |
|---|---|---|---|
| ZIP5 | 5 | No | X |
| Last Name | 5 | No | X |
| First Name | 5 | No | X |
| Company | 10 | No | X |
Add a database that contains the following fields:
| NAME: | Contains full names ("Mr. John Smith"). |
|---|---|
| COMPANY: | Contains company names ("Melissa Data"). |
| ADD1: | Contains first (primary) address line ("22382 Avenida Empresa"). |
| ADD2: | Contains second (secondary) address line ("Suite 34"). |
| CSZ: | Contains City/State/Zip ("Rancho Santa Margarita, CA 92688"). |
An application must create a link between a database's fields (Name, Company, Add1, Add2 and CSZ) and the matchcode components (Zip5, Last Name, First Name, Company).
With the example above, it may appear that the application will have to contain extensive splitting routines. This is not the case. All that is necessary is to tell MatchUp what type of data is in a specific field and the format of that data.
In the example above, an application would use the following matchcode mapping:
| Component | Database Field | Matchcode Mapping |
|---|---|---|
| ZIP5 | CSZ | CityStZip |
| Last Name | NAME | FullName |
| First Name | NAME | FullName |
| Company | COMPANY | Company |
This mapping tells MatchUP that the 5-digit ZIP Code information is in a field named "CSZ" which is described as a field containing city, state, and ZIP Code information. The Last Name can be found in a field called "NAME" and is described as a full name field (which is a full name sequenced: Pre, FN, MN, LN, Suf).
Five Mapping Rules
Matchcode mappings follow five rules:
- For every Matchcode Component, the application must specify a mapping. The only exception is described in rule 2.
- Actual Address components names (such as Street Number, Street Pre-Directional, Street Name, Street Suffix, Street Post-Directional, PO Box, and Street Secondary) are not listed for mapping purposes. Instead, the names Address Line 1, Address Line 2, and Address Line 3 are used. The example below used four address components in the matchcode (Street #, Street Name, Street Secondary, PO Box). However, it only used two address lines.
- If a matchcode uses any address components, Address Lines 1-3 will be listed after all other components regardless of where the address component appears in the matchcode. In the following example, the address components are listed before company in the matchcode, but Address Lines 1-2 are listed at the end (after company).
- If a matchcode uses address components, Address Lines 1-3 will require at least one line to be mapped, but not all. If a database only has one address field, an application will only need to map Address 1 to that field. All other components must be mapped.
- Address Lines should be mapped from the top down (Address Line1, then 2, then 3).
Enhancing the matchcode in the previous example:
| Component | Size | Fuzzy | 1 | 2 |
|---|---|---|---|---|
| ZIP5 | 5 | No | X | |
| Last Name | 5 | No | X | |
| First Name | 5 | No | X | |
| Street # | 5 | No | X | |
| Street Name | 5 | No | X | |
| Street Secondary | 12 | No | X | |
| PO Box | 10 | No | X | |
| Company | 10 | No | X | X |
Again, MatchUP doesn't use the individual address components. They are replaced with Address 1, Address 2, and Address 3. So, the application would use the following Matchcode Mapping:
| Matchcode Component | Database Field | Matchcode Mapping |
|---|---|---|
| ZIP9 | CSZ | CityStZip |
| Last Name | NAME | FullName |
| First Name | NAME | FullName |
| Company | COMPANY | Company |
| Address Line 1 | ADD1 | Address |
| Address Line 2 | ADD2 | Address |
| Address Line 3 | (none) |
Note on Rule #1:
If a database does not contain a field for information called for by a component in a matchcode, such as company field in the above example, then that matchcode should not be used to dedupe that database.
Use a different matchcode or modify an existing matchcode, as outlined later in this chapter.
However, if a matchcode calls for last name, for example, and the database only has full name, then simply map the full name field to the last name and MatchUP Object will handle parsing the field.
Optimization
Some matchcodes process much faster than others in spite of the fact that they detect the same matches. This section will assist in creating the most efficient matchcodes. Ninety-nine percent of the time, clicking the Optimize button in the Matchcode Editor will sufficiently optimize a matchcode. This discussion is included so developers can better understand why certain things are done while optimizing, as well as what can be done to make the optimizer work more effectively.
Optimizing can make a significant difference in processing speed. 58-hour runs have been reduced to four hours simply by optimizing the matchcode.
It is important, however, that the developer verifies that a matchcode works in the intended way before attempting any optimizations. If a matchcode is not functioning properly, these optimizations will not help, and could quite possibly make the situation worse.
Component Sequence
As discussed in the previous section, the first component of a matchcode has certain restrictions:
- It must be used in every combination.
- It cannot use certain types of Fuzzy Matching: Containment; Frequency; Fast Near; Frequency Near or Accurate Near (other types are okay, though).
- It cannot use Initial Only matching.
- It cannot use One Blank Field matching.
- It cannot use Swap matching.
If the matchcode's second component also follows these conditions, MatchUP Object will incorporate it into its clustering scheme (see page 3 for more information on clustering). Additional components, if they follow in sequence (third, fourth, and so on), will be used if they too satisfy these conditions. Incorporating a component into a cluster greatly reduces the number of comparisons MatchUP Object has to perform which, in turn, speeds up your processing.
This is a simple example of optimization:
| Component | Size | Fuzzy | Blank | 1 | 2 |
|---|---|---|---|---|---|
| ZIP/PC | 5 | No | Yes | X | X |
| Street # | 5 | No | Yes | X | |
| Street Name | 5 | No | No | X | |
| PO Box | 10 | No | No | X | |
| Last Name | 5 | No | Yes | X | X |
As shown here, MatchUP Object will only cluster by ZIP/PC. But note that the last component satisfies all the conditions listed earlier.
| Component | Size | Fuzzy | Blank | 1 | 2 |
|---|---|---|---|---|---|
| ZIP/PC | 5 | No | Yes | X | X |
| Last Name | 5 | No | Yes | X | X |
| Street # | 5 | No | Yes | X | |
| Street Name | 5 | No | No | X | |
| PO Box | 10 | No | No | X |
This simple optimization will produce significant improvements in speed. The Matchcode Optimizer will always perform this optimization.
Fuzzy Algorithms
Fuzzy algorithms fall into two categories: early matching and late matching.
Early matching algorithms are algorithms where a string is transformed into a (usually shorter) representation and comparisons are performed on this result. In MatchUP, these transformations are performed during key generation (the BuildKey function in each interface), which means that the early matching algorithms pay a speed penalty once per record: as each record’s key is built.
Late matching algorithms are actual comparison algorithms. Usually, one string is shifted in one direction or another, and often a matrix of some sort is used to derive a result. These transformations are performed during key comparison. As a result, late matching algorithms pay a speed penalty every time a record is compared to another record. This may happen several hundred times per record.
Obviously, late matching is much slower than early matching. If a particular matchcode is very slow, changing to a faster fuzzy matching algorithm may improve the speed. Often, a faster algorithm will give nearly the same results, but it is a good idea to test any such change before processing live data.
The fuzzy algorithms, ranked from slowest to fastest:
| Algorithm | Late or Early | Speed (10 = fastest) |
|---|---|---|
| Accurate Near | Late | 1 |
| Fast Near | Late | 3 |
| Containment | Late | 4 |
| Frequency Near | Late | 4 |
| Frequency | Late | 6 |
| Phonetex | Early | 7 |
| Soundex | Early | 8 |
| Vowels Only | Early | 9 |
| Numerics Only | Early | 9 |
| Consonants Only | Early | 9 |
| Alphas Only | Early | 9 |
| Exact | N/A | 10 |
The speed values are only rough estimates.
Another benefit of using a faster fuzzy algorithm is that an application may be able to exploit the component sequence optimization shown earlier. All of the early matching algorithms satisfy the restrictions for first components.
The Matchcode Optimizer will not perform this optimization as it can have a significant impact on matching results.
Unnecessary Components
Components that are not used in any combinations (in other words, they have no X's in columns 1 through 16) are a sign of poor matchcode design.
Take the following matchcode:
| Component | Size | Fuzzy | Blank | 1 | 2 |
|---|---|---|---|---|---|
| ZIP/PC | 5 | No | Yes | X | X |
| Last Name | 5 | No | Yes | X | X |
| First Name | 5 | No | Yes | ||
| Street # | 5 | No | Yes | X | |
| Street Name | 5 | No | No | X | |
| PO Box | 10 | No | No | X |
First name is not being used in any combination. Perhaps it was used in a combination that has since been removed from this matchcode, but is no longer necessary.
Unnecessary Combinations
Take the following matchcode:
| Component | Size | Fuzzy | Blank | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|---|---|
| ZIP5 | 5 | No | Yes | X | X | X | X |
| Last Name | 5 | No | Yes | X | X | X | X |
| First Name | 5 | No | Yes | ||||
| Street # | 5 | No | Yes | X | X | ||
| Street Name | 5 | No | No | X | X | ||
| PO Box | 10 | No | No | X | X |
Here are the four conditions for matching:
| Condition #1: | ZIP/PC | Last Name | First Name | Street # | Street Name | |
|---|---|---|---|---|---|---|
| Condition #2: | ZIP/PC | Last Name | First Name | PO Box | ||
| Condition #3: | ZIP/PC | Last Name | Street # | Street Name | ||
| Condition #4: | ZIP/PC | Last Name | PO Box |
There is no match that will be detected by condition #1 that would not be detected by condition #3. Similarly, matches found by condition #2 will always be found by condition #4. In other words, condition 3 is a subset of condition 1, and condition 2 is a subset of condition 4. Subsets are rarely desirable.
So either conditions 1 and 2 aren’t needed or conditions 3 and 4 were a mistake. If conditions 1 and 2 are eliminated, the First Name component should also be removed, as it will not be needed.
Swap Matching
Swap matching is used to catch matches when two fields are flipped around. The most common occasion is catching the "John Smith" and "Smith John" records. But there are other uses:
Comparing Household Records
When there are two or three first or full names per record, a list provider may claim that every record is always "husband, wife, then children," but records will read wife then child and husband:
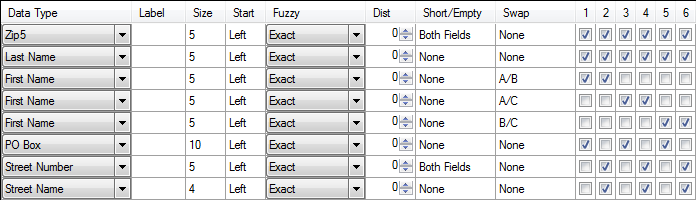
In the above example, select Either component can match for Swap Pairs A, B, and C
Comparing up to Three Address Lines
Although the address splitter works well in the US and Canada, some European countries can cause problems. A typical Euro-Matchcode will not use street split components and look at three address lines instead. The swap matching ensures that every address line is compared with every other address line.
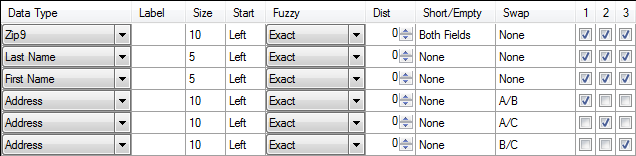
Again, select Either component can match for Swap Pairs A, B, and C.
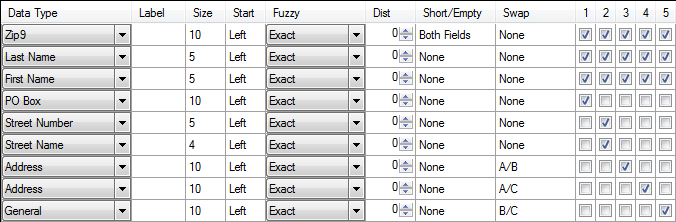
Don’t always discard the street split component matchcodes because you are working with a foreign database. Sometimes the street splitter will yield usable results. Therefore, a combination of approaches will often work.